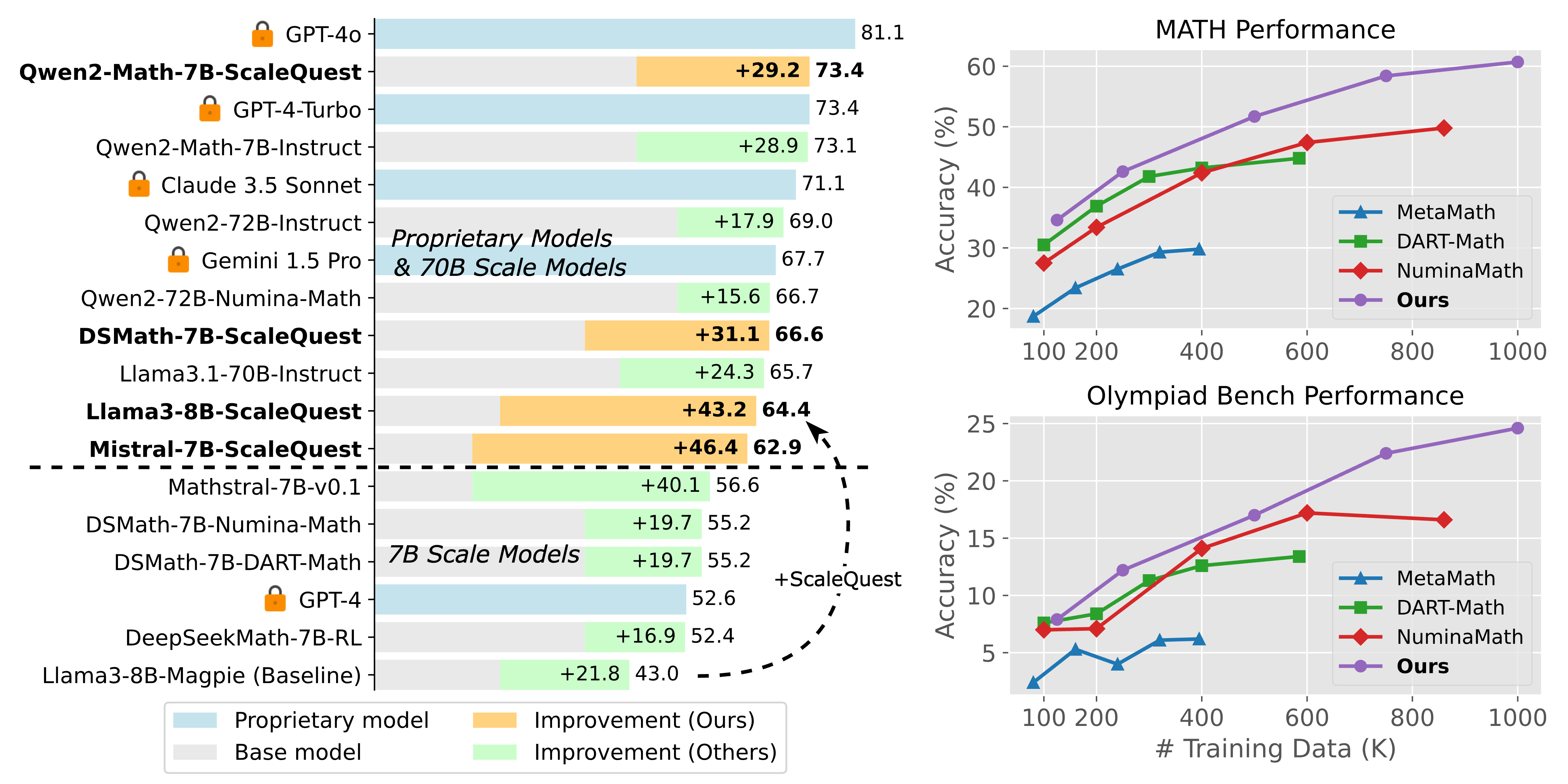
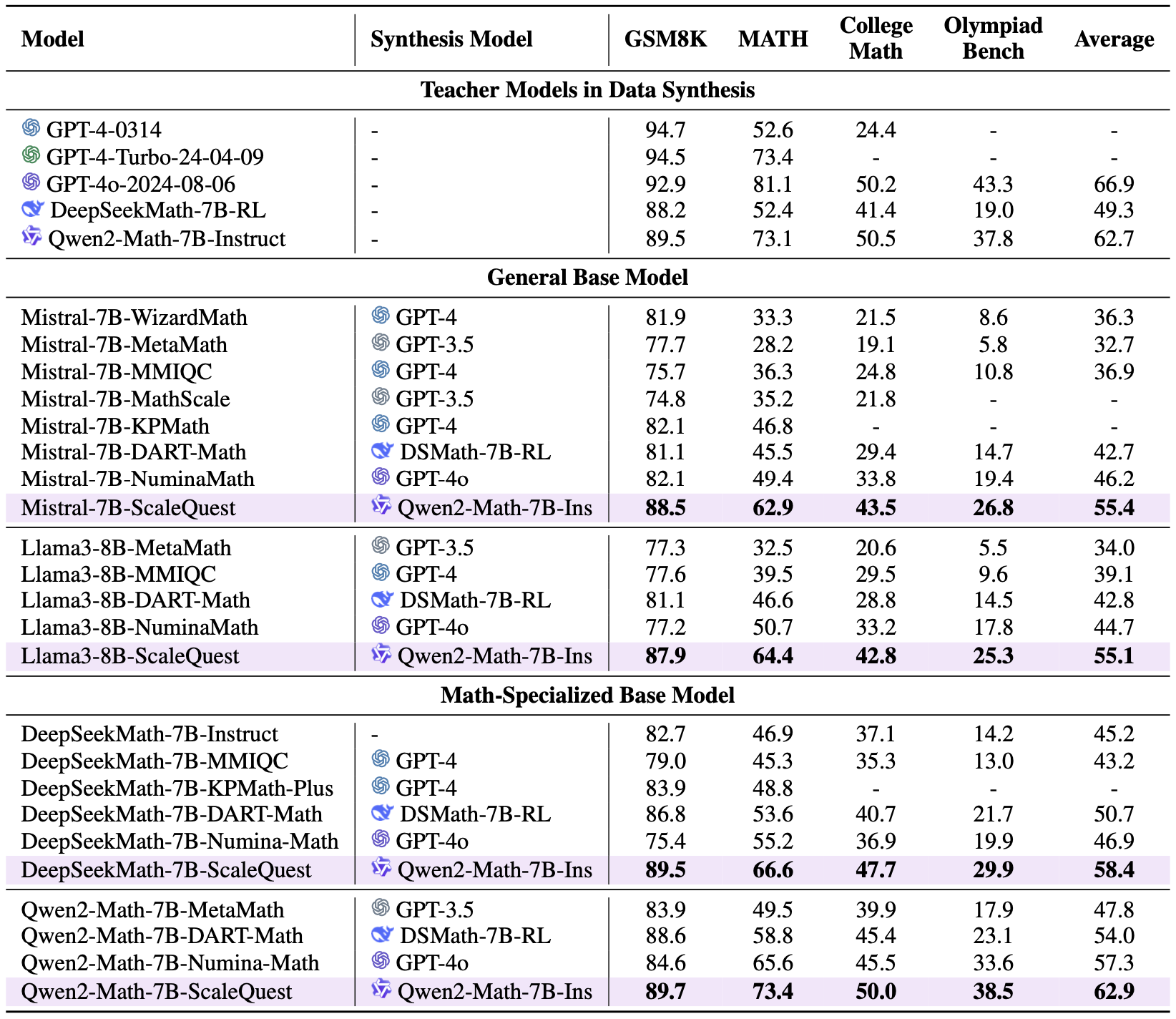
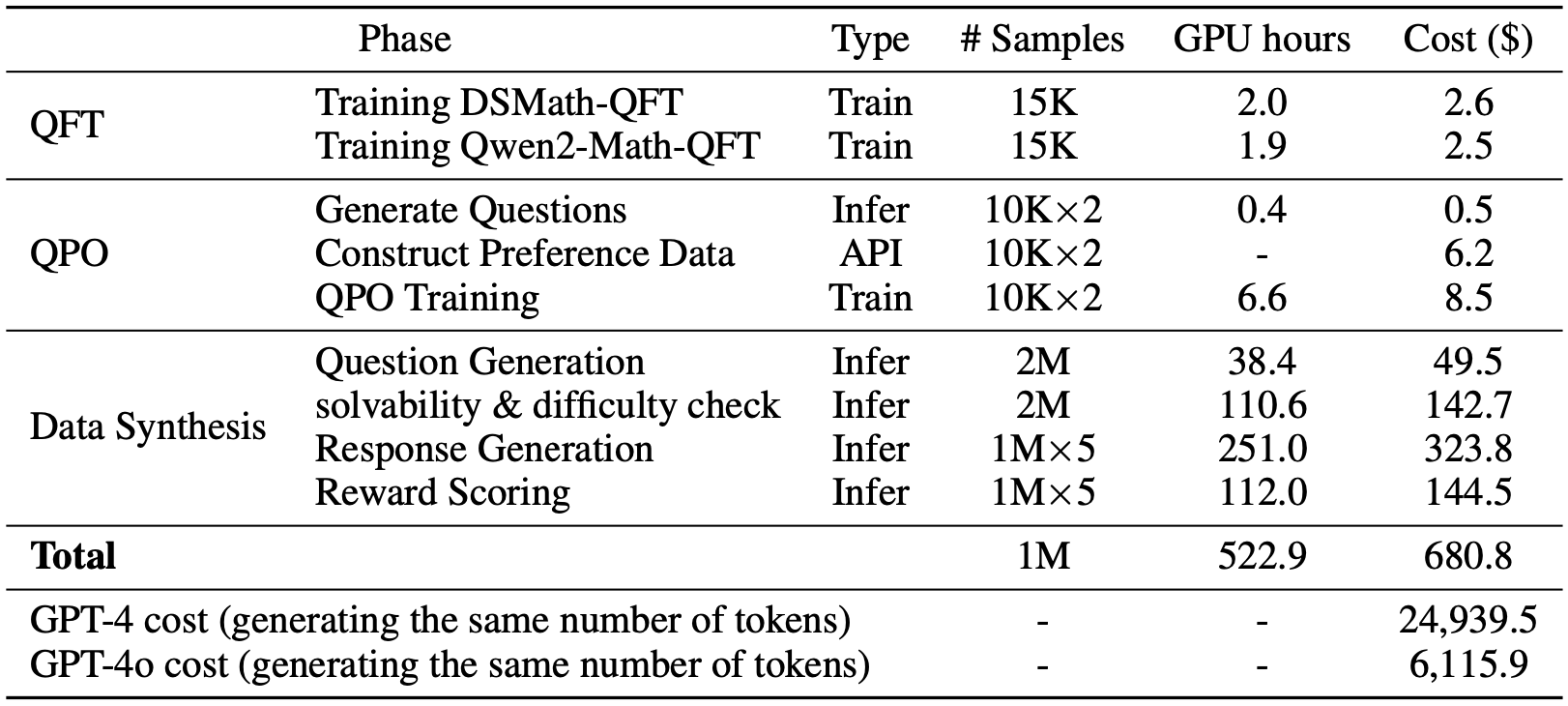
Method Overview
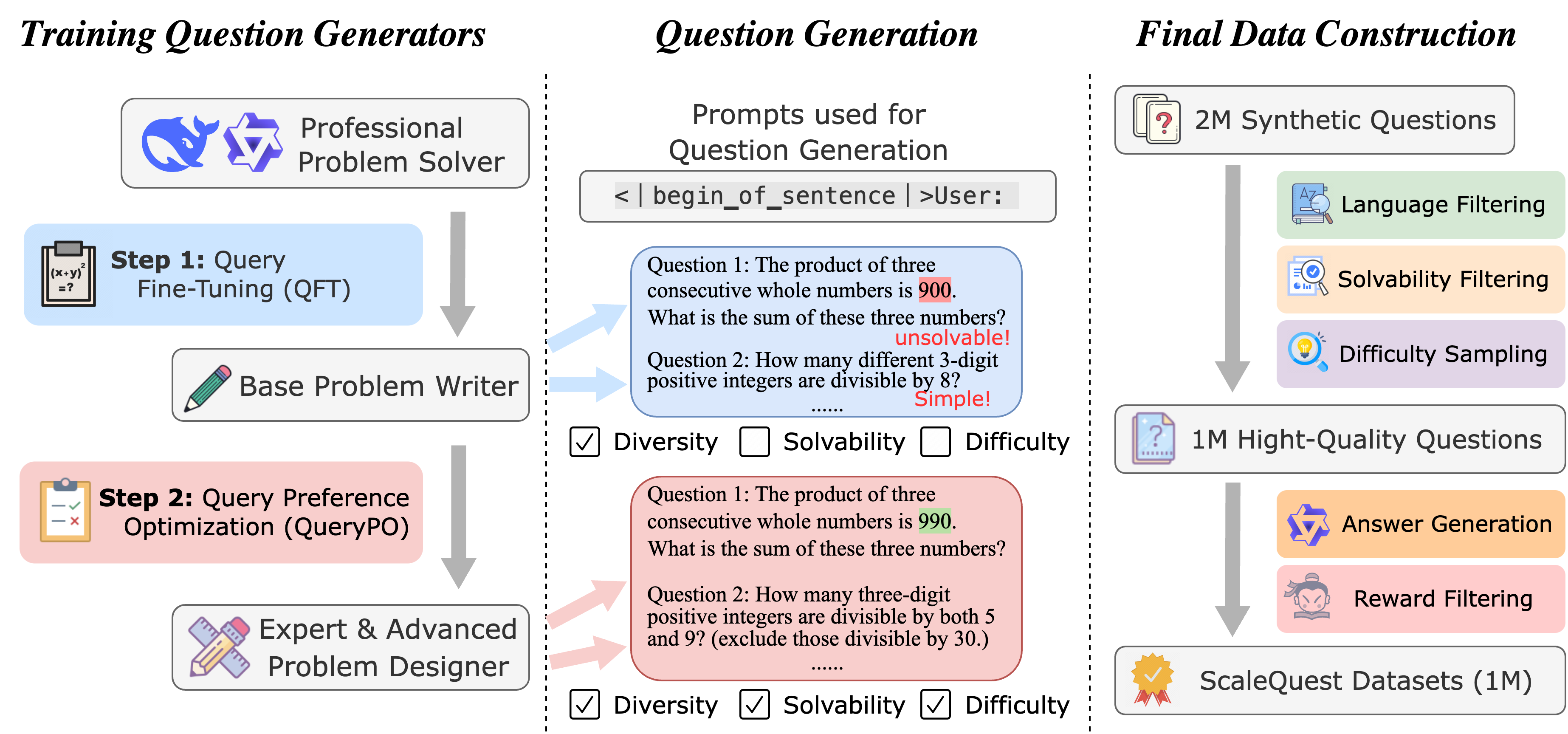
- Question Fine-Tuning (QFT): To activate the model's question generation capability, we first perform Question Fine-Tuning (QFT), where we train the problem-solving model using a small set of problems. We train two question generators based on DeepSeekMath-7B-RL and Qwen2-Math-7B-Instruct, using 15K problems from the GSM8K and MATH training set.
- Question Preference Optimization (QPO): We further optimize the two problem generators through preference tuning, focusing primarily on two aspects: problem solvability and difficulty.
- Question Filtering: After the QFT and QPO phases, we obtained two question generators: DeepSeekMath-QGen and Qwen2-Math-QGen. However, there were still some minor issues in the generated questions, so we applied filtering methods, including language filtering, solvability filtering, and difficulty sampling.
- Response Generation & Reward Filtering: We generate responses using Qwen2-Math-7B-Instruct and use the reward model score as a metric for evaluating response quality. The response with the highest reward score among the five candidates is then selected as the final response.